_db33a8.png)



.thumb.png.9594b08ba898a6b0d0fa1576ea2c9574.thumb.png.3097220ace298f0faaab6884cd0ea0f5.png)
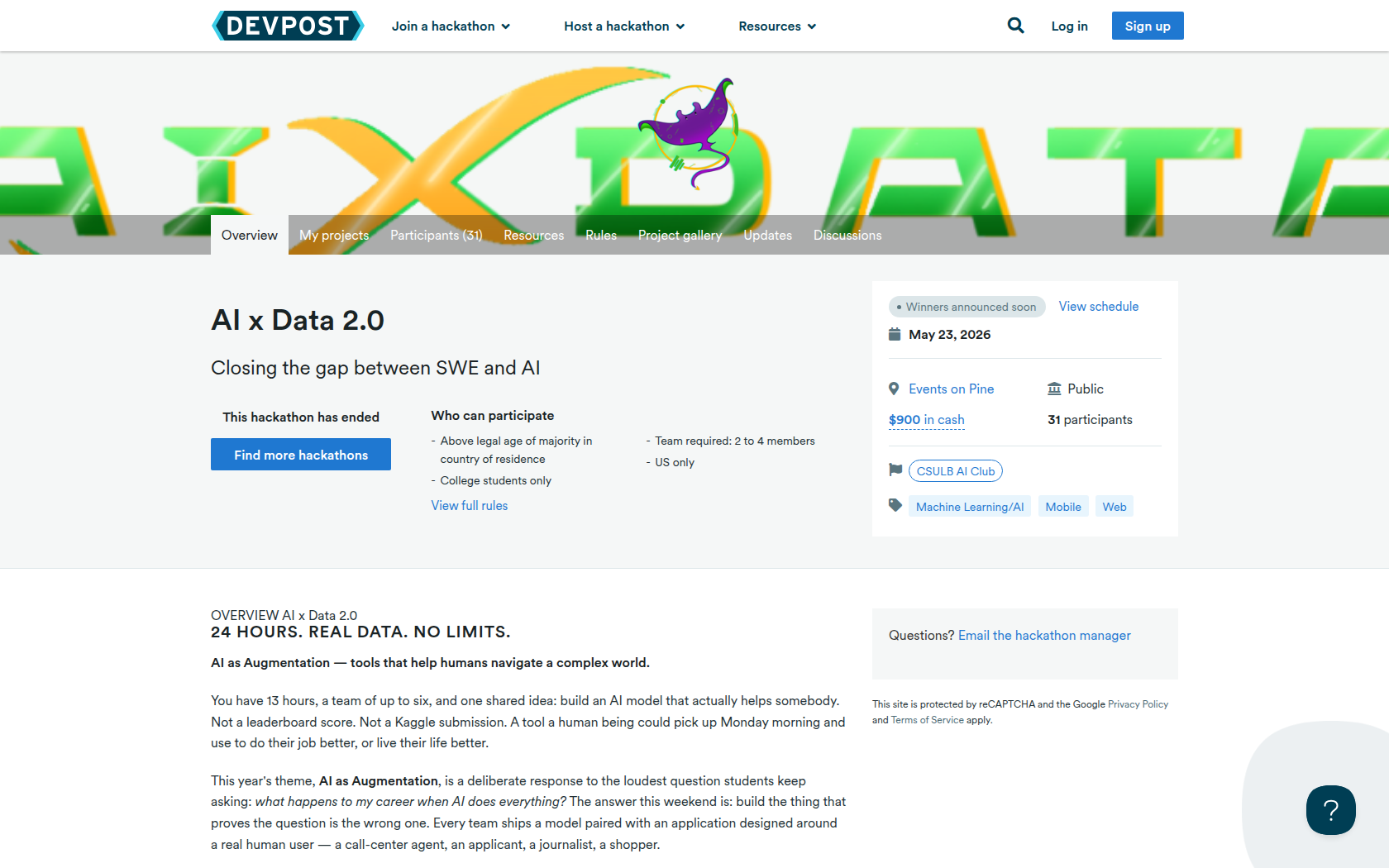
24 hours. Real data. No limits.
AI as Augmentation — tools that help humans navigate a complex world.
You have 13 hours, a team of up to six, and one shared idea: build an AI model that actually helps somebody. Not a leaderboard score. Not a Kaggle submission. A tool a human being could pick up Monday morning and use to do their job better, or live their life better.
This year's theme, AI as Augmentation, is a deliberate response to the loudest question students keep asking: what happens to my career when AI does everything? The answer this weekend is: build the thing that proves the question is the wrong one. Every team ships a model paired with an application designed around a real human user — a call-center agent, an applicant, a journalist, a shopper.
The model is the engine. The human is still the driver.
Four pillars. One theme.
You pick one pillar and stay there. Each is a different on-ramp into the same competition — winners are decided overall, not per pillar.
Pillar 01 · SML — Subscription Companion. Bank marketing data. Build a tool that helps a call-center agent have a better conversation — not a robocaller, not an auto-prioritizer. The agent uses your tool. Your tool doesn't use them.
Pillar 02 · USML — Find Your Cluster. Credit card applications, no labels. Build a tool that lets an applicant self-discover what cluster they fit into. Not so banks can pre-screen — so users can navigate.
Pillar 03 · CV — CIFAKE. 120,000 images, half real and half AI-generated. Build the model that helps a human tell the difference, in a world that increasingly can't.
Pillar 04 · NLP — Make Reviews Useful. 23,000 women's e-commerce clothing reviews. Turn review text into something useful for shoppers, merchants, or trend analysts.
A note on bias in the data. Two of the four datasets (Bank Marketing, Credit Card Applications) carry the historical biases of the systems they came from. We're not pretending the data is clean. You decide what features to keep, drop, transform, or audit — and you defend those choices in your Model Report. That conversation is part of how we judge this weekend.
Two days. One binding deadline.
📅 Day 1 — Friday, May 22 · Events on Pine · Downtown Long Beach 13-hour in-person build window. Check-in at 8 AM. Build begins 9:30 AM. Optional LoRA workshop at 3 PM. Dinner 6 PM. On-site build closes 10:30 PM — teams may keep working remotely afterward.
📅 Day 2 — Saturday, May 23 · CSULB Campus Submissions close hard at 10:00 AM Saturday on Devpost + GitHub. Judges score 10–11 AM. Live demos 10–11 AM in parallel pillar rooms. Winners announced 11:30 AM. Closing ceremony at noon.
What's on the line
🏆 Cash prizes for 1st / 2nd / 3rd — announced at the opening ceremony. 🤝 Industry judges, recruiters, and faculty in the room on Saturday. 💼 Direct hiring opportunities from sponsor companies actively recruiting from this event.
Whatever you ship this weekend — a half-baked notebook, a polished demo, a pivot at hour 11 — you'll know more on Sunday than you did on Friday. That's the whole point.
🔗 datathon26.com 📧 ai.researchcsulb@gmail.com
Requirements
Two places. One deadline.
All teams submit to both Devpost and a public GitHub repository by 8:00 AM Saturday, May 23. Late submissions are not accepted — Devpost closes automatically at the cutoff.
A · Devpost Project Page
☐ Project name & tagline — one line.
☐ Inspiration — the human user, the problem they face.
☐ What it does — clear, jargon-free.
☐ How we built it — architecture, data usage, key decisions.
☐ Challenges & what's next.
☐ Built with tags — languages, frameworks, models.
☐ Link to GitHub.
B · GitHub Repository
☐ Public repo — judges open it without login.
☐ README.md — overview, setup, run commands.
☐ requirements.txt or environment.yml.
☐ All training code — notebooks or .py files.
☐ All application code — the part users actually touch.
☐ Model artifacts — or a download link if too large.
☐ 1-page Model Report — approach, validation, limitations.
☐ Feature Choices and Trade-offs section in the Model Report — what you kept, what you dropped, why. Judges probe this in Q&A.
☐ predictions.csv for SML, CV, and NLP teams (USML teams do not submit predictions — you are scored on Cluster Quality & Insight).
Responsible AI statement
One paragraph, ≤200 words: who could be harmed by a misprediction, what is explicitly out of scope, and what guardrails the application has. Required for full credit on the Responsible AI portion of the Application Rubric. Teams that skip it cap themselves at 90 / 100 overall.
Judging — 100 points, half model, half product.
Three judges per pillar room score every team on two rubrics. 1st / 2nd / 3rd are decided overall, not per pillar.
Model Rubric (50 pts) — scored from your submission, Saturday 8–10 AM:
- Accuracy / Lift over baseline · 20 (USML: Cluster Quality & Insight)
- Data prep + Feature Choices and Trade-offs · 10
- Method selection & justification · 10
- Validation rigor · 5
- Reproducibility · 5
Application Rubric (50 pts) — scored from your live demo, Saturday 10–11 AM:
- Use case clarity & human impact · 15
- Product quality (live, end-to-end) · 15
- Presentation & storytelling · 10
- Responsible AI consideration · 5
- Q&A defense · 5
Live-demo logistics: 8 min presentation + 4 min Q&A + 3 min judge buffer. Parallel rooms, one per pillar. All team members should be present — non-coders explaining user impact often unlock the best presentation scores.
Prizes
TBA
To be announced at the ceremony
Devpost Achievements
Submitting to this hackathon could earn you:
Judges
Team Memebers
Judging Criteria
-
All

Recommended Comments
Join the conversation
You can post now and register later. If you have an account, sign in now to post with your account.